※ 본 포스팅은 스탠포드 대학의 "CS224n: Natural Language Processing with Deep Learning"1 강의를 수강하며 배운 것을 정리하기 위해 작성되었습니다. 모든 원문은 다음 링크에서 확인하실 수 있습니다. http://web.stanford.edu/class/cs224n/
Prerequisites for this course
- Proficiency in Python
- Multivariate Calculus, Linear Algebra
- Basic Probability and Statistics
- Fundamentals of Machine Learning(loss functions, taking simple derivatives, performing optimization with gradient descent)
Introduction to NLP and Deep Learning
1. 자연어처리 (NLP)
Natural Language Processing은 다음의 영역의 교집합이라고 할 수 있음
- 컴퓨터 과학
- 인공지능
- 언어학
NLP의 목표
유용한 업무 수행을 위해서 Natural Language자연 언어(사람의 언어)를 컴퓨터가 처리하고 이해할 수 있도록 하는 것임
예를 들면, 업무 수행, 예약하기, 물건 구매, 질문답변 등이 위에서 말한 유용한 업무수행이다.
speech 또는 text로부터 형태소를 분석해 syntactic analysis(의미적 분석)을 하고 그 의미를 해석할 수 있도록 하는 것이 전체적인 NLP 방향이라고 할 수 있다.
NLP의 응용분야
스펠링 및 맞춤법 검사, 키워드 검색, 동의어 발견 등이 있을 수 있고 웹사이트로부터 정보를 추출하거나 문서를 분류하는 등에도 활용될 수 있다. 그 외에 기계번역, 복잡한 질문에 대한 답변 등이 있을 수 있다.
NLP 산업
검색, 온라인 광고 매칭, 자동번역, 마케팅/금융에서의 감성분석, Speech Recognition, 챗봇 등에서 NLP가 활용된다.
Natural Language (인간의 언어에서 특별한 것은 무엇인가)
2. 딥러닝(Deep Learning)
= Describing data with features a computer can understand + Learning algorithm
Representation learning은 좋은 features 또는 representations를 자동적으로 학습하는 방법이다.
Deep learning 알고리즘은 (여러 단계로) representation과 output을 학습하는 방법이다. 보통 우리가 알고 있는 다층 layer를 생각하면 될 듯 하다.
딥러닝의 역사
Deep learning provides a very flexible, universal, learnable framework for representing world, visual and linguistic information.
- 많은 양의 학습 데이터
- 빠른 컴퓨팅 성능 (CPU/GPU)
- 새로운 모델, 알고리즘, 아이디어의 등장
위와 같은 시대적 변화와 함께 딥러닝은 재조명받아 현재 가장 인기있는 기계학습 방법이 되었으며 처음에는 speech와 video에서 향상된 성능 입증했지만 이제는 NLP로 그 영역이 확장되었다.
딥러닝 for Speech

딥러닝 for Computer Vision

NLP는 다음과 같은 이유로 어려운 분야이다.
- 복잡하다 (representing, learning & using linguistic/situational/world/visual knowledge)
- 애매하다 (인간의 언어는 프로그래밍과 다른 formal 언어와는 다르다)
- 의존적임 (인간의 언어를 해석하기 위해서는 실제 세상과 상식, 문맥정보 등이 필요하다)
Deep Learning으로 NLP 문제를 해결하는 것이 목표이다.
최근 NLP와 관련하여 큰 개선이 있었다.
- Levels: speech, words, syntax, semantics
- Tools: parts-of-speech, entities, parsing
- Applications: machine translation, sentiment analysis, dialogue agents, question answering
|
|
과거 |
딥러닝(현재) |
|
Levels (Morphology) |
언어는 형태소(morphemes)로 구성되어 있다 Unkindness => Prefix + Root + Suffix |
모든 형태소는 하나의 벡터이다. 신경망(neural network(은 두개의 벡터를 하나의 벡터로 합치는 것이다 unfortunately = unfortunate + ly = (un + fortunate) + ly |
|
Levels (Semantics) |
Lambda Calculus |
모든 단어와 모든 구문(phrase), 모든 논리적표현은 하나의 벡터이다. |
|
Tools (Parsing sentence structure) |
|
신경망은 정확하게 문장의 구조를 이해하고 해석을 돕는다 |
|
Applications (Sentiment Anlaysis) |
다른 말뭉치(bag-of-words)와 결합된 감성사전 또는 직접 만든 negation features를 사용하여 감성분석 단어의 순서를 무시하고 모든 것을 파악하지는 못하는 문제있음 |
RecursiveNN을 통해 morphology, syntax, logical semantics 학습 가능 |
|
… |
… |
… |
*원문에서 나머지 Applications 내용과 이해를 돕는 그림을 통해 좀더 쉽게 이해할 수 있음

출처: https://myndbook.com/view/4914
2017/09/19 - [Data Science/NLP with Deep Learning] - 딥러닝으로 NLP 하자 (2) - word2vector, Word Vectors 기초
한줄 개인적인 요약
딥러닝은 신경망 모형의 각 하나의 벡터에 하나의 단어/구문... 레벨을 대응해서 학습하는 방식인듯 함.
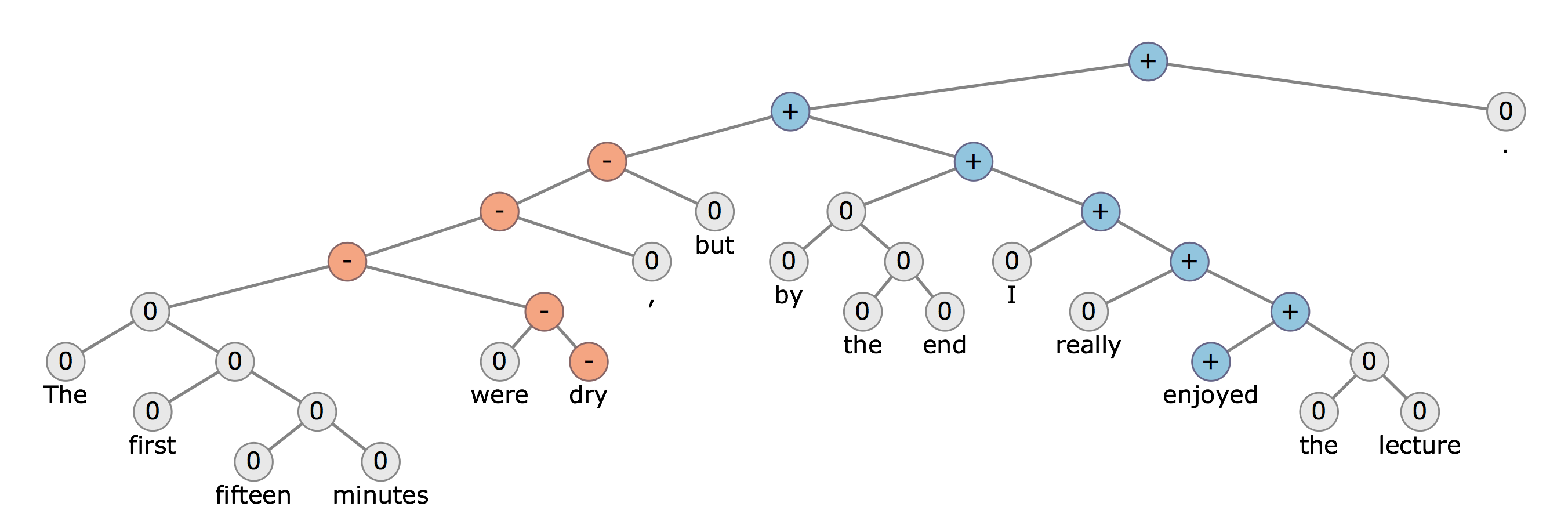
그림. Deep Learning으로 Sentimental Analysis(감성분석) 하기3
- Stanford Edu. CS224n: Natural Language Processing with Deep Learning. http://web.stanford.edu/class/cs224n [본문으로]
- Dahl, George E. et al. “Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition.” IEEE Transactions on Audio, Speech, and Language Processing 20 (2012): 30-42. [본문으로]
- CS224d: Deep Learning for Natural Language Processing. http://cs224d.stanford.edu/ [본문으로]
'Data Science > NLP with Deep Learning' 카테고리의 다른 글
| NTN으로 시작하는 자연어처리와 딥러닝 (4) - 모델 학습 (0) | 2019.02.22 |
|---|---|
| NTN으로 시작하는 자연어처리와 딥러닝 (3) - NTN 신경망 구조 파악 및 이론적 배경 탐색 (3) | 2018.02.14 |
| NTN으로 시작하는 자연어처리와 딥러닝 (2) - 일단 NTN 알기 : 새로운 사실의 발견 (0) | 2018.02.07 |
| NTN으로 시작하는 자연어처리와 딥러닝 (1) - 핵심개념 살펴보기 (0) | 2018.02.07 |
| NTN으로 시작하는 자연어처리와 딥러닝 (0) - 들어가기 앞서 (0) | 2018.02.06 |
| 딥러닝으로 NLP 하자 (2) - word2vector, Word Vectors 기초 (3) | 2017.09.19 |


댓글