파이썬 코드 변환 - 밑바닥부터 시작하는 데이터 과학 中
※본 포스팅은 "밑바닥부터 시작하는 데이터 과학"을 공부하면서 4장 선형대수를 NumPy로 소스코드를 변경하면서 그리고 본문의 내용을 익히기 위해 작성하였습니다.
선형대수 Linear Algebra
선형대수는 문사철인 내게 처음 들어보는 말이다. 하지만 또 개념적으로 그 내용을 들어보니 또 전혀 새로운 것은 아니었다. 프로그래밍을 하면서 나도 모르게 알게된 내용도 있었으며 벡터 공간이라는 것도 철학을 공부했을 때 들었던 내용이기도 하다. 정확한 기억은 나지 않지만 아마 서양근대철학을 공부했을 때 정확히 선형대수는 아니었지만 비슷한 개념적 내용을 접했던 것으로 기억한다.
1. 벡터 Vectors
2. 행렬 Matrix
3. 브로드캐스팅 Broadcasting
1. 벡터 Vectors
NLP를 딥러닝으로 하는 방법을 공부하면서 벡터에 대해서 좀 더 살펴볼 수 있는 기회가 있었고, 한 무림고수의 비법서를 보면서 그 기초를 짚어가고 있다. 거기에서는 벡터를 '수의 순서쌍'이라고도 불렀다. 방향이 있고 순서가 있고 차원의 공간에 존재하는 점이라고도 할 수 있다.
하나의 리스트에 3개의 값을 넣으면 3차원의 벡터를 표현했다고 볼 수 있다. 그렇다고 list가 벡터인 것은 아니다.
기초적인 것중 하나로 벡터의 차원이 다르면 덧셈을 할 수가 없다. 3차원 벡터 + 4차원 벡터
ex. (1, 2, 3) + (1, 2, 3) = (2, 4, 6) // (1, 2, 3) + (1, 2) X
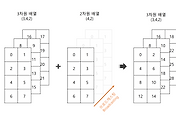
벡터 간 합(+)연산
파이썬의 list로 벡터를 눈으로 표현할 수 있지만 list를 통해서 위와 같은 벡터연산을 하기는 어렵다. list1 + list2는 각 순서끼리의 값을 더한 새로운 결과 값을 가진 list3을 생성하는 것이 아닌 list1, list2가 연결된 값이 출력된다.
1 2 3 | a = [1, 2] b = [1, 2] print (a + b) #결과: [1, 2, 1, 2] | cs |
이를 NumPy를 활용하면 쉽게 벡터 연산을 할 수 있다. (NumPy에 대해 더 알고 싶다면 본 블로그의 다른 포스팅 NumPy 기본을 참고하자)
1 2 3 4 | import numpy as np a = np.array([1, 2]) b = np.array([1, 2]) print (a + b) #결과: array([2, 4]) | cs |
벡터와 스칼라(상수) 곱 연산
벡터의 상수 곱 연산도 NumPy를 활용하면 쉽게 할 수 있다. 책의 예제에서는 리스트 컴프리헨션을 사용하여 리스트의 각 원소를 하나씩 빼서 상수와 곱하고 다시 리스트로 생성하는 함수를 만들었다. 아래는 확장성은 떨어지는 코드지만 map함수를 사용해서 벡터(lista)와 스칼라(2)의 곱연산을 구해보았다.
1 2 3 | lista = [1,2,3,4,5] scalar_multiply = list(map(lambda x: x*2,lista)) #결과는 [2,4,6,8,10] | cs |
이를 NumPy를 활용하면 쉽게 또 된다.
1 2 3 | lista = np.array([1,2,3,4,5]) lista * 2 #결과는 array([2,4,6,8,10]) | cs |
벡터의 내적 (Dot Product)
벡터의 내적이라는 용어가 처음에는 무엇인지 몰랐다. 간단히 말하면 벡터의 각 원소끼리 곱한 후 모두 더한 값을 말한다. 그 값은 스칼라(상수) 형태로 나타난다. ex. (1, 2) * (2, 1) = (1 * 2) + (2 * 1) = 4
내적은 보통 벡터A가 벡터B 방향으로 얼마나 멀리 뻗어나가는지를 나타낸다.
이를 NumPy를 활용하면 또또 쉽게 된다
1 2 3 | a = np.array([1,2,3,4,5]) b = np.array([2,4,6,8,10]) print (sum(a*b)) #결과: 110 | cs |
두 벡터 간의 거리
두 벡터 간의 거리를 계산하기 위해서도 많은 것이 필요하지 않다. 직관적으로 수식을 입력해도 쉽게 결과 값이 나온다.

1 2 3 | a = np.array([1,2,3,4,5]) b = np.array([2,4,6,8,10]) print (sum((a-b)**2))**(1/2)) #결과: 7.416198..... | cs |
n x n 단위행렬
단위행렬은 대각선의 원소가 1이고 나머지 원소는 0인 행렬을 말한다. 아래는 NumPy의 diag method를 활용해서 예제를 똑같이 구현해 보았다.
1 2 3 4 5 6 7 | np.diag([1 for _ in range(5)]) #결과 #array([[1,0,0,0,0], # [0,1,0,0,0], # [0,0,1,0,0], # [0,0,0,1,0], # [0,0,0,0,1]]) | cs |
2. 행렬
행렬은 벡터의 모음이라고도 볼 수 있다. 3차원의 벡터가 2개 있으면 2행, 3열의 행렬이 있다고 말할 수 있다. 하나의 벡터 안에서 원소의 값이 같은 성질을 가지며 이러한 벡터가 쌓인 게 행렬이라고도 볼 수 있다. 책에서는 다음의 이유로 행렬이 중요할 것이라고 말한다.
- 행렬은 여러 벡터로 구성된 데이터셋으로 표현될 수 있음
- k차원의 벡터를 n차원의 벡터로 변환해주는 선형함수를 n x k 행렬로 표현 가능함
- 행렬로 이진 관계(binary relationship)를 나타낼 수 있음
선형대수에서도 정말 기초 중의 기초만 다루었다. 정말 밑바닥만 한다. 하지만 그만큼 또 많은 내용을 다루며 추가적인 공부가 필요한 사람들에게는 소스도 제공해준다. 미리 알고 읽었으면 큰 도움이 되었을 것 같다. 책의 제목중 From Scratch라는 표현이 뭔가 크게 와닿는다. scratch라는 말 그대로 '긁으면서' 배워가고 있으니 말이다.
하나하나 필요한 것들을 배워나가면서 정말 긁어가며 배우고 있는 것 같다. 상처도 많이 나고 힘도 들지만 그만큼 얻는 것도 많다. 그리고 내가 공부한 심리학과 철학, 경영학 등이 데이터 과학을 이해하는데에도 많은 도움이 되고 있다. 이것에 대해서는 차차 정리하려고 한다.
'Data Science > 파이썬으로 데이터분석 하기' 카테고리의 다른 글
| 파이썬으로 데이터 분석하자 (5) - Matplotlib 기본 (2) | 2017.12.08 |
|---|---|
| 파이썬으로 데이터분석하자 (4) - Pandas 기본 (7) | 2017.12.06 |
| 파이썬으로 데이터 분석하자 (3) - NumPy 기본 (4) | 2017.10.09 |
| Python 기초 - NumPy Broadcasting 이해하기 (2) (1) | 2017.10.09 |
| 파이썬으로 데이터 분석하자 (2) - IPython 사용하기 (1) | 2017.09.27 |
| Python 기초 - 일급함수(first-class)란 무엇인가 (2) | 2017.09.20 |
| 파이썬으로 데이터 분석하자 (1) (1) | 2017.09.19 |
댓글