2017/09/27 - 문과생도 이해하는 딥러닝 (1) - 퍼셉트론 Perceptron
2017/10/18 - 문과생도 이해하는 딥러닝 (2) - 신경망 Neural Network
2017/10/25 - 문과생도 이해하는 딥러닝 (3) - 오차 역전파, 경사하강법
2017/12/24 - 문과생도 이해하는 딥러닝 (4) - 신경망구현, 활성화함수, 배치
2017/12/26 - 문과생도 이해하는 딥러닝 (5) - 신경망 학습 실습
2018/01/05 - 문과생도 이해하는 딥러닝 (6) - 오차역전파법 실습 1
2018/01/05 - 문과생도 이해하는 딥러닝 (7) - 오차역전파법 실습 2
2018/01/07 - 문과생도 이해하는 딥러닝 (8) - 신경망 학습 최적화
2018/01/07 - 문과생도 이해하는 딥러닝 (9) - 신경망 초기 가중치 설정
어느덧 10번째 포스팅이 됐다. 슬슬 다음 코스로는 무엇을 할지 고민해야 겠다.
이전 포스팅에서는 초기 가중치 설정에 따라서 활성화 값의 분포가 어떻게 나타나는지 파악했으며 활성화함수 별로 적절한 초기 가중치 설정 방법이 있다는 것을 알았다. 이번에는 또다른 이슈에 대해 다루고자 한다. 4번째 포스팅에서 배치(Batch)에 대해서 포스팅을 했었다. 배치는 일종의 랜덤 샘플링으로 전체 학습데이터를 한 번 학습할 때 다 학습에 사용하면 많은 시간이 걸리기 때문에... (수천만, 수억 개의 데이터를 한 번에 다 사용한다면???) 미니배치 방식으로 랜덤하게 학습 데이터에서 배치 크기만큼 꺼내서 한 번의 학습에 사용하는 방식이다.
이번 포스팅에서 다루는 배치 정규화는 초기 가중치 설정 문제와 비슷하게 가중치 소멸 문제(Gradient Vanishing) 또는 가중치 폭발 문제(Gradient Exploding)를 해결하기 위한 접근 방법 중 하나이다. 정규화(Normalization)는 통계에서 다루는 정규화를 말한다. 기본적인 개념으로 사용되기 때문에 먼저 이를 숙지해야 된다.
배치 정규화 Batch Normalization
문과생도 이해하는 딥러닝 (10)
1. 배치 정규화 도입
학습의 효율을 높이기 위해 도입되었다. 배치 정규화는 Regularization을 해준다고 볼 수 있음
- 학습 속도가 개선된다 (학습률을 높게 설정할 수 있기 때문)
- 가중치 초깃값 선택의 의존성이 적어진다 (학습을 할 때마다 출력값을 정규화하기 때문)
- 과적합(overfitting) 위험을 줄일 수 있다 (드롭아웃 같은 기법 대체 가능)
- Gradient Vanishing 문제 해결
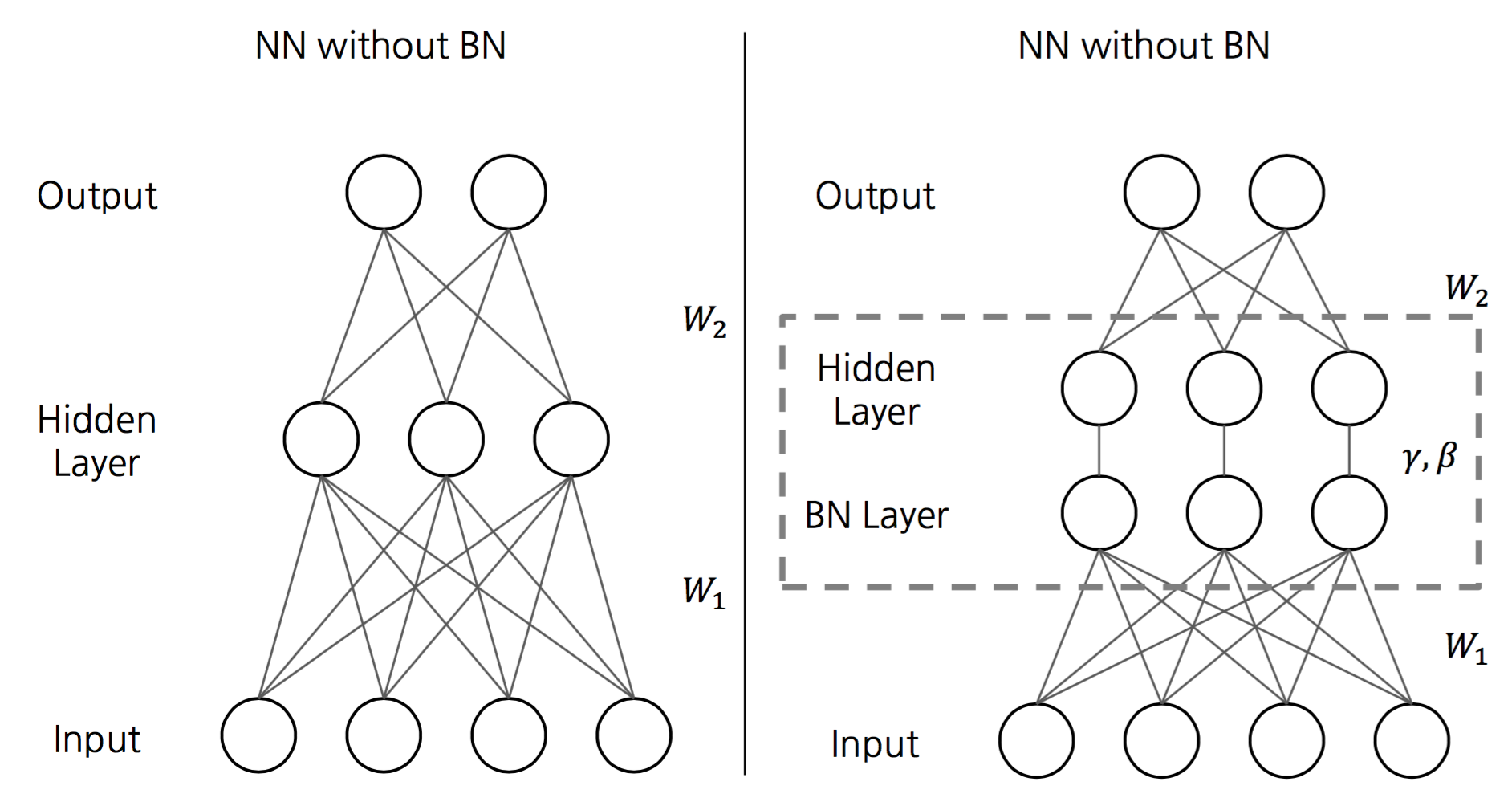
입력 분포의 균일화

2. 배치 정규화 알고리즘


3. 기타 참고

Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariance Shift
"Training 할 때는 mini-batch의 평균과 분산으로 normalize 하고, Test 할 때는 계산해놓은 이동 평균으로 normalize 한다. Normalize 한 이후에는 scale factor와 shift factor를 이용하여 새로운 값을 만들고, 이 값을 내놓는다. 이 Scale factor와 Shift factor는 다른 레이어에서 weight를 학습하듯이 back-prop에서 학습하면 된다."
출처 :
https://shuuki4.wordpress.com/2016/01/13/batch-normalization-%EC%84%A4%EB%AA%85-%EB%B0%8F-%EA%B5%AC%ED%98%84/
참고자료
- Batch Normalization (ICML 2015)
http://sanghyukchun.github.io/88/ - Normalization in Deep Learning
https://calculatedcontent.com/2017/06/16/normalization-in-deep-learning/ - Batch Normalization 설명 및 구현
https://shuuki4.wordpress.com/2016/01/13/batch-normalization-%EC%84%A4%EB%AA%85-%EB%B0%8F-%EA%B5%AC%ED%98%84/ - Layer Normalization
https://www.slideshare.net/ssuser06e0c5/normalization-72539464 - 배치정규화 (Batch Normalization)
http://astralworld58.tistory.com/65
'Data Science > 문과생도 이해하는 딥러닝' 카테고리의 다른 글
| 문과생도 이해하는 딥러닝 (11) - 가중치 감소, 드롭아웃 (2) | 2018.01.07 |
|---|---|
| 문과생도 이해하는 딥러닝 (9) - 신경망 초기 가중치 설정 (4) | 2018.01.07 |
| 문과생도 이해하는 딥러닝 (8) - 신경망 학습 최적화 (6) | 2018.01.07 |
| 문과생도 이해하는 딥러닝 (7) - 오차역전파법 실습 2 (0) | 2018.01.05 |
| 문과생도 이해하는 딥러닝 (6) - 오차역전파법 실습 1 (0) | 2018.01.05 |
| 문과생도 이해하는 딥러닝 (5) - 신경망 학습 실습 (7) | 2017.12.26 |
| 문과생도 이해하는 딥러닝 (4) - 신경망구현, 활성화함수, 배치 (10) | 2017.12.24 |
| 문과생도 이해하는 딥러닝 (3) - 오차 역전파, 경사하강법 (2) | 2017.10.25 |
댓글